밑바닥부터 시작하는 딥러닝 1 | 신경망 1
밑바닥부터 시작하는 딥러닝 1 Chapter 3 정리
책 정보 📖
- 책 제목: 밑바닥부터 시작하는 딥러닝 1
- 글쓴이: 사이토 고키
- 옮긴이: 개앞맵시
- 출판사: 한빛미디어
- 발행일: 2025년 01월 24일
- 챕터: Chapter 3. 신경망
책소개
딥러닝 분야 부동의 베스트셀러! 머리로 이해하고 손으로 익히는 가장 쉬운 딥러닝 입문서 이 책은 딥러닝의 핵심 개념을 ‘밑바닥부터’ 구현해보며 기초를 한 걸음씩 탄탄하게 다질 수 있도록 도와주는 친절한 안내서입니다. 라이브러리나 프레임워크에 의존하지 않고 딥러닝의 기본 개념부터 이미지 인식에 활용되는 합성곱 신경망(CNN)까지 딥러닝의 원리를 체계적으로 설명합니다. 또한 복잡한 개념은 계산 그래프를 활용해 시각적으로 전달하여 누구나 쉽게 이해할 수 있습니다. 이 책은 딥러닝에 첫발을 내딛는 입문자는 물론이고 기초를 다시금 다지고 싶은 개발자와 연구자에게도 훌륭한 길잡이가 되어줄 것입니다.
주요 내용
신경망의 기초: 퍼셉트론을 넘어서다
퍼셉트론에서 한 걸음 더 나아가면 신경망(Neural Network)을 만날 수 있다. 퍼셉트론이 가중치를 수동으로 설정해야 했다면, 신경망은 적절한 값을 데이터로부터 자동으로 학습하여 설정하는 능력을 갖추게 된다. 이것이 바로 현대 딥러닝의 핵심이다.
퍼셉트론에서 신경망으로
신경망의 구조
신경망은 크게 세 부분으로 구성된다:
- 입력층(Input Layer): 데이터가 들어오는 층
- 은닉층(Hidden Layer): 입력과 출력 사이의 중간 처리 층
- 출력층(Output Layer): 최종 결과가 나오는 층
은닉층의 뉴런은 입력층이나 출력층과 달리 사람 눈에는 보이지 않는다. 만약 은닉층이 1층이라면 이전에 배운 퍼셉트론과 다를 바가 없다.
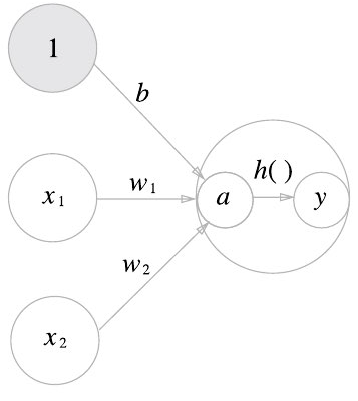 편향과 활성화 처리 과정이 명시된 퍼셉트론
편향과 활성화 처리 과정이 명시된 퍼셉트론
퍼셉트론의 동작을 수식으로 정리하면 다음과 같다:
\[y = h(b + w_1x_1 + w_2x_2) = h(x)\] \[h(x) = \begin{cases}0 \ (x \leq 0)\\1\ (x > 0)\end{cases}\]활성화 함수의 등장
여기서 h(x) 함수와 같이 입력 신호의 총합을 출력 신호로 변환하는 함수를 활성화 함수(Activation Function)라 한다.
퍼셉트론 vs 신경망
- 단순 퍼셉트론: 단층 네트워크에서 계단 함수를 활성화 함수로 사용
- 다층 퍼셉트론(신경망): 여러 층으로 구성되고 시그모이드 함수 등의 매끈한 활성화 함수를 사용
다양한 활성화 함수들
계단 함수(Step Function)
계단 함수는 임곗값을 경계로 출력이 바뀌는 함수다.
1
2
3
4
5
6
7
8
9
10
import numpy as np
import matplotlib.pyplot as plt
def step_function(x):
return np.array(x > 0, dtype=int)
# 넘파이를 이용한 계단 함수 처리 예시
x = np.array([-1.0, 1.0, 2.0])
y = x > 0 # [False, True, True]
y = y.astype(int) # [0, 1, 1]
계단 함수 시각화
1
2
3
4
5
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
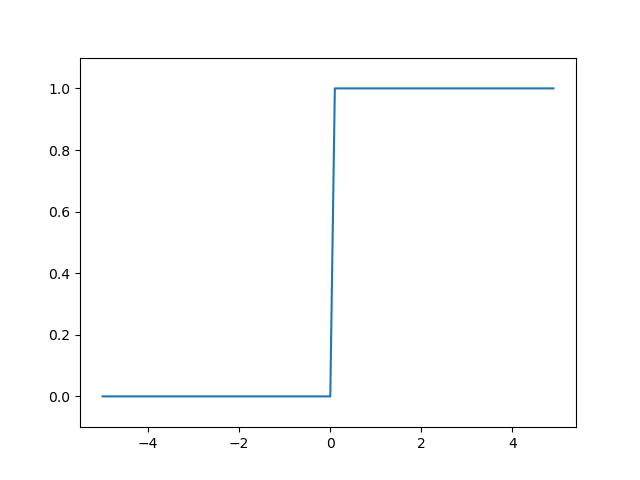 계단 함수 그래프
계단 함수 그래프
시그모이드 함수(Sigmoid Function)
시그모이드 함수는 ‘S자 모양’이라는 뜻으로, 다음과 같은 수식을 가진다:
\[h(x) = \frac{1}{1 + exp(-x)}\]1
2
3
4
5
6
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 넘파이의 브로드캐스트 활용
x = np.array([-1.0, 1.0, 2.0])
result = sigmoid(x) # [0.26894142, 0.73105858, 0.88079708]
시그모이드 함수 시각화
1
2
3
4
5
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
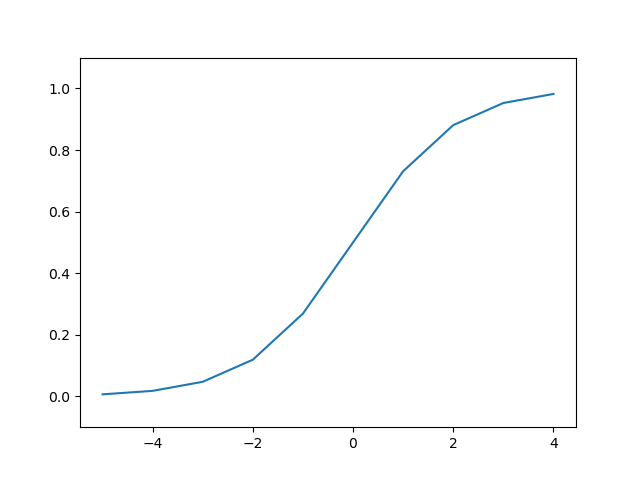 시그모이드 함수 그래프
시그모이드 함수 그래프
ReLU 함수(Rectified Linear Unit)
최근 가장 널리 사용되는 활성화 함수다. 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하면 0을 출력한다.
1
2
def relu(x):
return np.maximum(0, x)
ReLU 함수 시각화
1
2
3
4
5
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.ylim(-0.1, 5.1)
plt.show()
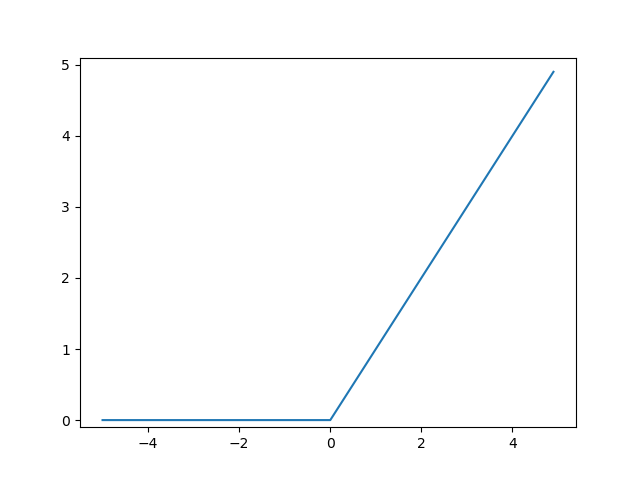 ReLU 함수 그래프
ReLU 함수 그래프
활성화 함수 비교 분석
시그모이드 vs 계단 함수
차이점
- 시그모이드: 부드러운 곡선, 연속적인 출력 변화
- 계단 함수: 0을 경계로 갑작스러운 출력 변화
- 매끈함의 중요성: 시그모이드의 연속성이 신경망 학습에서 중요한 역할을 한다
- 데이터 흐름: 퍼셉트론은 0 또는 1, 신경망은 연속적인 실수가 흐른다
공통점
- 입력이 작으면 0에 가깝고, 입력이 커지면 1에 가까워진다
- 출력 범위가 0에서 1 사이로 제한된다
- 둘 다 비선형 함수다
비선형 함수의 중요성
선형 함수를 활성화 함수로 사용하면 신경망의 층을 깊게 하는 의미가 없어진다.
선형 함수의 문제점:
- 층을 아무리 깊게 해도 ‘은닉층이 없는 네트워크’와 동일한 기능
- 예시:
h(x) = cx라면y(x) = h(h(h(x))) = c³x = ax - 결국 하나의 층으로 표현 가능하다
따라서 여러 층의 이점을 살리려면 비선형 활성화 함수가 필수다.
다차원 배열로 신경망 구현하기
넘파이의 다차원 배열을 사용하면 신경망을 효율적으로 구현할 수 있다.
다차원 배열 기초
1
2
3
4
5
6
7
8
9
# 1차원 배열
A = np.array([1, 2, 3, 4])
print(np.ndim(A)) # 1 (차원 수)
print(A.shape) # (4,) (형상)
# 2차원 배열
B = np.array([[1, 2], [3, 4], [5, 6]])
print(np.ndim(B)) # 2
print(B.shape) # (3, 2)
행렬의 곱
신경망의 핵심은 행렬의 곱이다. A의 열 수와 B의 행 수가 같아야 계산이 가능하다.
1
2
3
A = np.array([[1, 2], [3, 4], [5, 6]]) # (3, 2)
B = np.array([7, 8]) # (2,)
result = np.dot(A, B) # [23, 53, 83]
신경망에서의 행렬 곱
1
2
3
4
5
6
7
8
9
# 입력 데이터
X = np.array([1, 2]) # (2,)
# 가중치 행렬
W = np.array([[1, 3, 5], # (2, 3)
[2, 4, 6]])
# 순전파 계산
Y = np.dot(X, W) # [5, 11, 17]
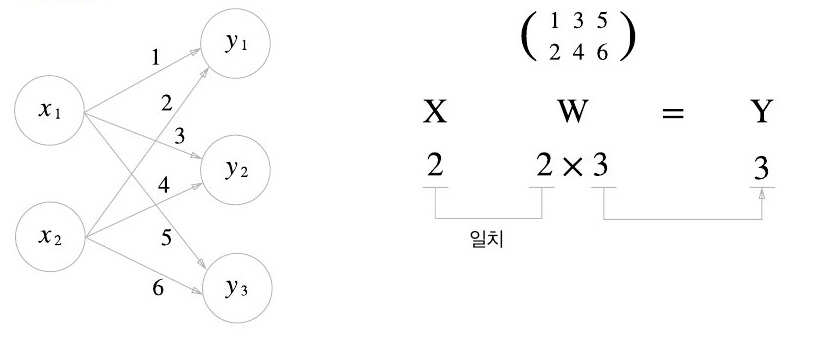 신경망을 행렬 곱으로 표현
신경망을 행렬 곱으로 표현
이렇게 행렬 곱을 활용하면 Y의 원소가 100개든 1000개든 한 번의 연산으로 계산이 가능해진다. 이것이 바로 넘파이를 활용한 벡터화의 힘이다.
마무리
신경망은 퍼셉트론의 한계를 뛰어넘는 강력한 도구다. 적절한 활성화 함수 선택과 효율적인 행렬 연산을 통해 복잡한 패턴을 학습할 수 있다.
특히 비선형 활성화 함수의 도입은 신경망이 단순한 선형 변환을 넘어 복잡한 함수를 근사할 수 있게 해주는 핵심 요소다. 다음 단계에서는 이러한 기초를 바탕으로 실제 신경망을 구현하고 학습시키는 방법을 살펴보겠다.