밑바닥부터 시작하는 딥러닝 1 | 신경망 2
밑바닥부터 시작하는 딥러닝 1 Chapter 3 정리
책 정보 📖
- 책 제목: 밑바닥부터 시작하는 딥러닝 1
- 글쓴이: 사이토 고키
- 옮긴이: 개앞맵시
- 출판사: 한빛미디어
- 발행일: 2025년 01월 24일
- 챕터: Chapter 3. 신경망
책소개
딥러닝 분야 부동의 베스트셀러! 머리로 이해하고 손으로 익히는 가장 쉬운 딥러닝 입문서 이 책은 딥러닝의 핵심 개념을 ‘밑바닥부터’ 구현해보며 기초를 한 걸음씩 탄탄하게 다질 수 있도록 도와주는 친절한 안내서입니다. 라이브러리나 프레임워크에 의존하지 않고 딥러닝의 기본 개념부터 이미지 인식에 활용되는 합성곱 신경망(CNN)까지 딥러닝의 원리를 체계적으로 설명합니다. 또한 복잡한 개념은 계산 그래프를 활용해 시각적으로 전달하여 누구나 쉽게 이해할 수 있습니다. 이 책은 딥러닝에 첫발을 내딛는 입문자는 물론이고 기초를 다시금 다지고 싶은 개발자와 연구자에게도 훌륭한 길잡이가 되어줄 것입니다.
주요 내용
신경망 구현하기: 이론에서 실습까지
앞서 신경망의 기본 개념을 살펴보았다면, 이제 실제로 3층 신경망을 구현해본다. 이론을 코드로 옮기는 과정에서 신경망의 동작 원리를 더 깊이 이해할 수 있다.
3층 신경망 구현하기
표기법 정리
신경망을 구현하기 전에 수학적 표기법을 명확히 하자.
가중치 표기법: \(w^{(1)}_{1 \ 2}\)
(1): 1층의 가중치1 2: 다음 층 1번째 뉴런, 앞 층 2번째 뉴런
뉴런 표기법: \(a^{(1)}_{1}\)
- 1층의 첫 번째 뉴런
각 층의 신호 전달 과정
신경망에서 신호가 어떻게 전달되는지 단계별로 살펴보자.
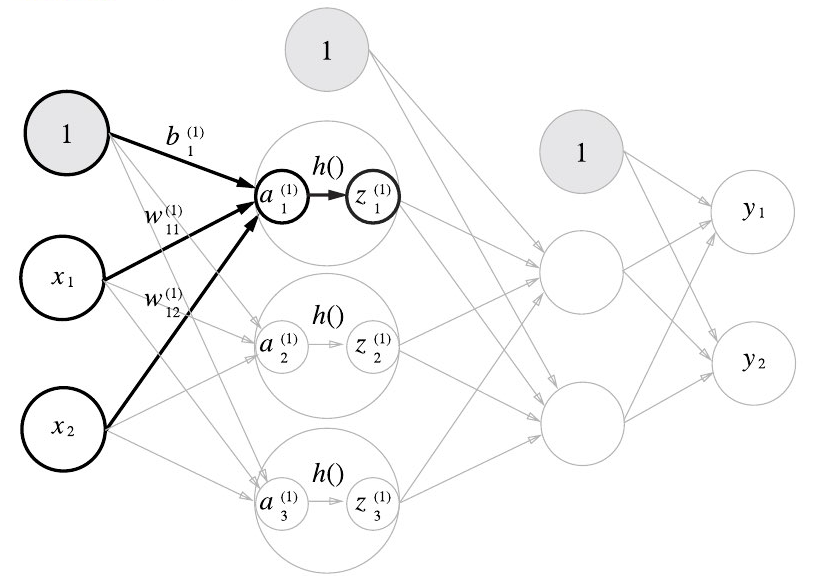 입력층에서 1층으로 신호 전달
입력층에서 1층으로 신호 전달
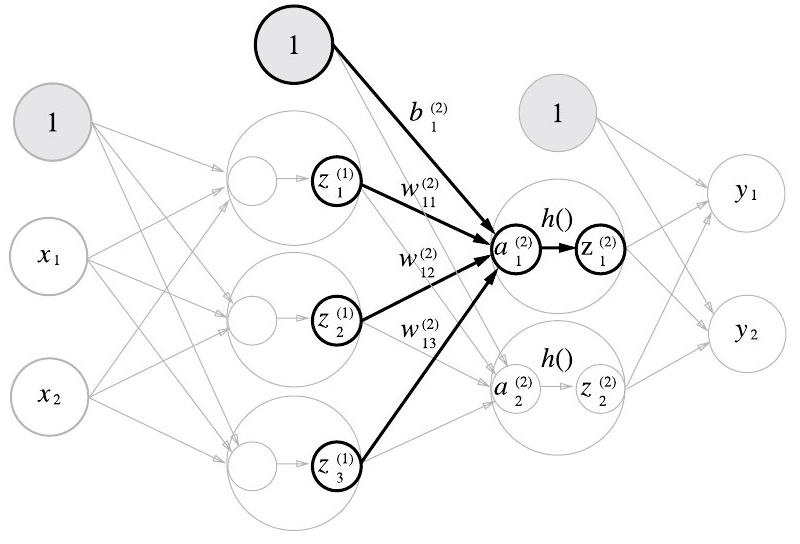 1층에서 2층으로 신호 전달
1층에서 2층으로 신호 전달
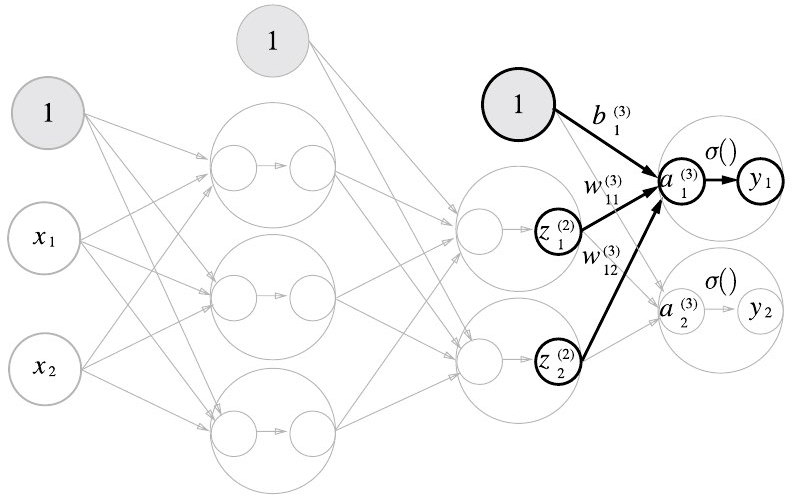 2층에서 출력층으로 신호 전달
2층에서 출력층으로 신호 전달
출력층의 특징:
- 출력층에서는 활성화 함수로 항등 함수를 사용한다
- 활성화 함수는 풀고자 하는 문제의 성질에 맞게 정한다:
- 회귀: 항등 함수
- 2클래스 분류: 시그모이드 함수
- 다중 클래스 분류: 소프트맥스 함수
신경망 구현 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(x):
return x
# 가중치와 편향을 초기화 후 딕셔너리에 저장
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# 입력 신호를 출력 신호로 변환하는 순전파 과정
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
# 실행
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
이것이 바로 신경망의 순전파(Forward Propagation) 구현이다.
출력층 설계하기
신경망은 회귀와 분류 문제 모두에 사용할 수 있다. 문제 유형에 따라 출력층의 활성화 함수를 적절히 선택해야 한다.
머신러닝 문제 유형
- 분류: 데이터가 어느 클래스에 속하는지 판단
- 회귀: 입력 데이터에서 연속적인 수치를 예측
소프트맥스 함수 구현
다중 클래스 분류에서 사용하는 소프트맥스 함수의 수식은 다음과 같다:
\[y_k = \frac{\exp(a_k)}{\sum_{i=1}^n \exp(a_i)}\]1
2
3
4
5
6
7
8
9
10
11
12
13
import numpy as np
# 기본 소프트맥스 함수
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 예시 실행
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y) # [0.01821127 0.24519181 0.73659691]
오버플로우 문제 해결
소프트맥스 함수에서 지수 함수 계산 시 오버플로우가 발생할 수 있다.
1
2
3
4
# 문제 상황
a = np.array([1010, 1000, 990])
result = np.exp(a) / np.sum(np.exp(a))
print(result) # [nan, nan, nan]
해결 방법: 소프트맥스 함수는 분자와 분모에 같은 상수를 곱해도 결과가 바뀌지 않는다:
\[y_k = \frac{\exp(a_k + C')}{\sum_{i=1}^{n} \exp(a_i + C')}\]1
2
3
4
5
6
7
8
9
10
11
12
# 개선된 소프트맥스 함수
def softmax(a):
c = np.max(a) # 입력 신호 중 최댓값
exp_a = np.exp(a - c) # 오버플로우 방지
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 해결된 결과
a = np.array([1010, 1000, 990])
y = softmax(a)
print(y) # [9.99954600e-01, 4.53978686e-05, 2.06106005e-09]
소프트맥스 함수의 특징
1
2
3
4
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y) # [0.01821127 0.24519181 0.73659691]
print(np.sum(y)) # 1.0
주요 특징:
- 출력 범위: 0과 1 사이의 실수
- 총합: 모든 출력의 합이 1
- 확률 해석: 각 출력을 확률로 해석 가능
- 순서 보존: 입력의 대소 관계가 출력에서도 유지
실용적 고려사항:
- 추론 단계에서는 소프트맥스 함수를 생략해도 된다 (순서가 바뀌지 않으므로)
- 학습 단계에서는 소프트맥스 함수를 사용한다
- 지수 함수 계산 비용을 줄이기 위해 추론 시 생략하는 것이 일반적이다
손글씨 숫자 인식 실습
이제 실제 데이터를 사용해 신경망을 구현해보자. 이미 학습된 매개변수를 사용해 추론 과정만 구현한다.
MNIST 데이터셋
MNIST는 머신러닝 분야에서 가장 유명한 손글씨 숫자 데이터셋이다:
- 28×28 픽셀의 흑백 이미지
- 0~9 숫자 분류
- 훈련 이미지와 테스트 이미지로 구성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
# 데이터 로드
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# 첫 번째 이미지 확인
img = x_train[0]
label = t_train[0]
print(f"Label: {label}") # 5
print(f"Image shape: {img.shape}") # (784,)
# 이미지 시각화
img = img.reshape(28, 28)
img_show(img)
x_train: 학습 이미지 데이터, t_train: 학습 라벨 (0~9 숫자), x_test: 테스트 이미지 데이터, t_test: 테스트 라벨
신경망 추론 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(
normalize=True, flatten=True, one_hot_label=False
)
return x_test, t_test
def init_network():
# 미리 학습된 가중치 매개변수 로드
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
# 성능 평가
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)): # 10,000개 테스트 이미지
y = predict(network, x[i])
p = np.argmax(y) # 확률이 가장 높은 클래스
if p == t[i]:
accuracy_cnt += 1
print(f"Accuracy: {float(accuracy_cnt) / len(x)}") # 약 93.52%
핵심 구성 요소:
- 입력층: 784개 뉴런 (28×28 이미지)
- 출력층: 10개 뉴런 (0~9 숫자)
- 정규화: 0~255 픽셀 값을 0.0~1.0으로 변환
배치 처리로 성능 향상하기
하나씩 처리하는 대신 여러 이미지를 한 번에 처리하는 배치 처리를 사용하면 성능을 크게 향상시킬 수 있다.
배치 처리의 장점
- 수치 계산 최적화: 라이브러리가 큰 배열을 효율적으로 처리
- I/O 부하 감소: 데이터를 읽는 횟수가 줄어듦
- 병렬 처리: CPU/GPU가 더 효율적으로 동작
배치 처리 구현
1
2
3
4
5
6
7
8
9
10
11
# 배치 처리 적용
batch_size = 100
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1) # 배치 단위로 최대값 인덱스
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print(f"Accuracy: {float(accuracy_cnt) / len(x)}")
핵심 변화:
np.argmax(y_batch, axis=1): 각 이미지별로 최대값 인덱스 찾기axis=1: 1차원 방향(각 이미지)으로 최대값 검색
마무리
이번 장에서는 신경망의 실제 구현 방법을 배웠다. 퍼셉트론에서 시작해 3층 신경망까지 구현하며, 실제 손글씨 숫자 인식 문제를 해결해보았다.
핵심 포인트:
- 순전파: 입력에서 출력으로 신호가 전달되는 과정
- 활성화 함수: 문제 유형에 맞는 함수 선택의 중요성
- 배치 처리: 성능 향상을 위한 필수 기법
- 전처리: 입력 데이터 정규화의 필요성