밑바닥부터 시작하는 딥러닝 1 | 신경망 학습 3
밑바닥부터 시작하는 딥러닝 1 Chapter 4 정리
책 정보 📖
- 책 제목: 밑바닥부터 시작하는 딥러닝 1
- 글쓴이: 사이토 고키
- 옮긴이: 개앞맵시
- 출판사: 한빛미디어
- 발행일: 2025년 01월 24일
- 챕터: Chapter 4. 신경망 학습
책소개
딥러닝 분야 부동의 베스트셀러! 머리로 이해하고 손으로 익히는 가장 쉬운 딥러닝 입문서 이 책은 딥러닝의 핵심 개념을 ‘밑바닥부터’ 구현해보며 기초를 한 걸음씩 탄탄하게 다질 수 있도록 도와주는 친절한 안내서입니다. 라이브러리나 프레임워크에 의존하지 않고 딥러닝의 기본 개념부터 이미지 인식에 활용되는 합성곱 신경망(CNN)까지 딥러닝의 원리를 체계적으로 설명합니다. 또한 복잡한 개념은 계산 그래프를 활용해 시각적으로 전달하여 누구나 쉽게 이해할 수 있습니다. 이 책은 딥러닝에 첫발을 내딛는 입문자는 물론이고 기초를 다시금 다지고 싶은 개발자와 연구자에게도 훌륭한 길잡이가 되어줄 것입니다.
주요 내용
신경망 학습 구현: 이론을 실제로 만들기
지금까지 손실 함수, 기울기, 경사법의 이론을 배웠다. 이제 이 모든 것을 결합하여 실제로 학습하는 2층 신경망을 구현한다. 데이터로부터 자동으로 매개변수를 학습하는 과정을 살펴본다.
신경망에서의 기울기
기울기의 의미
신경망 학습에서 기울기는 가중치 매개변수에 대한 손실 함수의 기울기다.
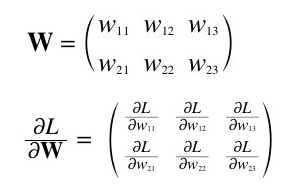 가중치와 기울기 수식
가중치와 기울기 수식
가중치가 W이고 손실 함수가 L인 신경망에서 $\frac{\partial L}{\partial W}$의 각 원소는 해당 가중치에 관한 편미분이다.
중요한 포인트: $\frac{\partial L}{\partial W}$의 형상이 W와 같다는 것이다. 이는 각 가중치가 손실 함수에 미치는 영향을 정확히 대응시켜 보여준다.
간단한 신경망으로 기울기 확인하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class simpleNet:
def __init__(self):
# 정규분포로 가중치 초기화 (편향 없음)
self.W = np.random.randn(2, 3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x) # 예측 수행
y = softmax(z) # 활성화 함수
loss = cross_entropy_error(y, t) # 손실 함수
return loss
# 사용 예시
x = np.array([0.6, 0.9]) # 입력
t = np.array([0, 0, 1]) # 정답 레이블 (원-핫 인코딩)
net = simpleNet()
# 손실 함수를 람다 함수로 정의
f = lambda w: net.loss(x, t)
# 기울기 계산
dW = numerical_gradient(f, net.W)
print(dW)
# 출력 예시:
# [[ 0.42027315 0.11048601 -0.53075916]
# [ 0.63040973 0.16572901 -0.79613874]]
기울기 해석:
- $\frac{\partial L}{\partial w_{11}} = 0.42…$: $w_{11}$을 h만큼 증가시키면 손실이 $0.42 \times h$만큼 증가
- $\frac{\partial L}{\partial w_{23}} = -0.79…$: $w_{23}$을 h만큼 증가시키면 손실이 $0.79 \times h$만큼 감소
- 손실을 줄이려면 양수 기울기는 음의 방향으로, 음수 기울기는 양의 방향으로 갱신해야 한다
학습 알고리즘 구현하기
신경망 학습의 4단계
신경망에는 적응 가능한 가중치와 편향이 있다. 이 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정을 ‘학습’이라고 한다. 신경망 학습은 다음 4단계를 반복하는 과정이다:
1단계: 미니배치
훈련 데이터 중 일부를 무작위로 선택한다. 선별한 데이터를 미니배치라 하며, 미니배치의 손실 함수 값을 줄이는 것이 목표다.
2단계: 기울기 산출
미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구한다. 기울기는 손실 함수의 값을 가장 작게 하는 방향을 제시한다.
3단계: 매개변수 갱신
가중치 매개변수를 기울기 방향으로 아주 조금 갱신한다.
4단계: 반복
1~3단계를 반복한다.
이 방법을 확률적 경사 하강법(SGD, Stochastic Gradient Descent)이라고 한다. 데이터를 미니배치로 무작위 선정하기 때문에 ‘확률적’이라는 용어를 사용한다.
2층 신경망 클래스 구현
실제 학습 가능한 신경망을 클래스로 구현해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# 오차역전파법을 이용한 효율적인 기울기 계산
# (구현 생략 - 다음 장에서 자세히 다룸)
pass
클래스 구성 요소:
- params: 신경망의 매개변수를 보관하는 딕셔너리
- grads: 기울기를 보관하는 딕셔너리
- 가중치 초기화: 가중치는 정규분포 난수, 편향은 0으로 초기화
- numerical_gradient: 수치 미분으로 기울기 계산 (느리지만 정확)
- gradient: 오차역전파법으로 기울기 계산 (빠르고 정확)
미니배치 학습 구현
실제 MNIST 데이터를 사용해 2층 신경망을 학습시켜보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
# 하이퍼파라미터
iters_num = 10000 # 반복 횟수
train_size = x_train.shape[0] # 60,000
batch_size = 100 # 미니배치 크기
learning_rate = 0.1 # 학습률
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 1에포크당 반복 수
iter_per_epoch = max(train_size / batch_size, 1) # 600번
for i in range(iters_num):
# 1단계: 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 2단계: 기울기 계산
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 더 빠른 방법
# 3단계: 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1에포크마다 정확도 계산
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(f"train acc: {train_acc:.4f}, test acc: {test_acc:.4f}")
에포크(Epoch)의 개념
에포크는 훈련 데이터를 모두 소진했을 때의 횟수를 나타내는 단위다.
- 훈련 데이터 60,000개를 100개씩 미니배치로 학습
- 600회 반복하면 모든 데이터를 한 번씩 사용 → 1에포크
- 10,000번 반복 ≈ 약 16.7에포크
학습 결과 분석
손실 함수 변화
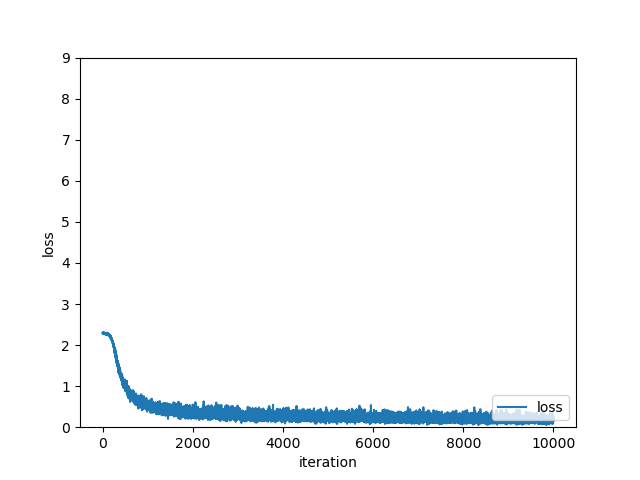 학습횟수가 늘어가면서 손실 함수의 값이 줄어듬
학습횟수가 늘어가면서 손실 함수의 값이 줄어듬
1
2
3
4
5
6
# 손실 함수 그래프 그리기
plt.plot(range(len(train_loss_list)), train_loss_list, label='loss')
plt.xlabel("iteration")
plt.ylabel("loss")
plt.legend()
plt.show()
관찰 결과:
- 학습이 진행될수록 손실 함수 값이 지속적으로 감소
- 경사 하강법이 올바르게 작동하고 있음을 확인
- 초기에는 급격히 감소하다가 점차 완만해짐
정확도 변화
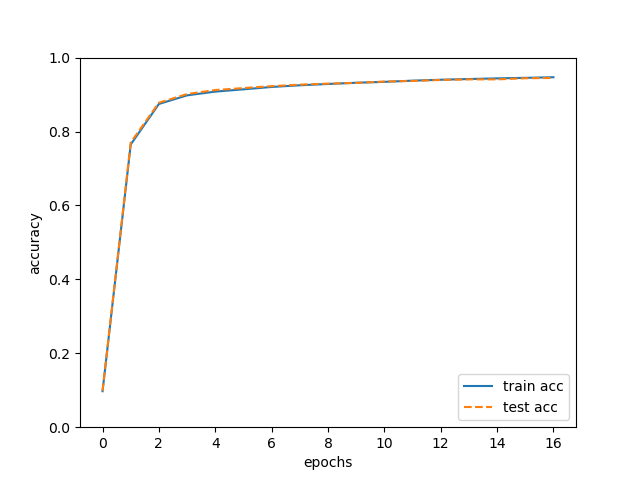 훈련 데이터와 시험 데이터에 대한 정확도 추이
훈련 데이터와 시험 데이터에 대한 정확도 추이
1
2
3
4
5
6
7
8
# 정확도 그래프 그리기
epochs = np.arange(len(train_acc_list))
plt.plot(epochs, train_acc_list, label='train acc')
plt.plot(epochs, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()
관찰 결과:
- 훈련 데이터와 시험 데이터의 정확도가 모두 향상
- 두 정확도 사이에 큰 차이가 없음
- 과대적합이 발생하지 않았음을 의미
과대적합과 대응 방법
과대적합이란?
과대적합(Overfitting): 훈련 데이터에만 지나치게 적응하여 새로운 데이터에 대한 성능이 떨어지는 현상
과대적합 발생 시 현상:
- 훈련 정확도는 계속 향상
- 시험 정확도는 어느 순간부터 하락
- 두 정확도 사이의 격차가 점점 벌어짐
과대적합 방지 기법
1. 조기 종료(Early Stopping)
- 시험 데이터 정확도가 떨어지기 시작하는 순간 학습 중단
- 가장 간단하고 효과적인 방법
2. 가중치 감소(Weight Decay)
- 가중치가 너무 커지지 않도록 제약 추가
- 손실 함수에 가중치의 L2 노름을 추가
3. 드롭아웃(Dropout)
- 학습 시 일부 뉴런을 무작위로 비활성화
- 네트워크의 복잡성을 줄여 일반화 성능 향상
마무리
신경망 학습의 전체 과정을 구현해보았다. 미니배치 SGD를 통해 손실 함수를 최소화하고, 훈련 데이터와 시험 데이터를 모니터링하여 과대적합을 방지하는 것이 핵심이다.
핵심 포인트:
- SGD: 미니배치를 사용한 확률적 경사 하강법
- 에포크: 전체 데이터를 한 번 사용하는 단위
- 모니터링: 훈련/시험 정확도를 함께 관찰
- 과대적합 방지: 조기 종료, 가중치 감소, 드롭아웃
다음 장에서는 기울기를 더 효율적으로 계산하는 오차역전파법(Backpropagation)을 배우게 된다. 수치 미분보다 훨씬 빠르면서도 정확한 기울기 계산이 가능해진다.