밑바닥부터 시작하는 딥러닝 1 | 학습 관련 기술들 1
밑바닥부터 시작하는 딥러닝 1 Chapter 6 정리
책 정보 📖
- 책 제목: 밑바닥부터 시작하는 딥러닝 1
- 글쓴이: 사이토 고키
- 옮긴이: 개앞맵시
- 출판사: 한빛미디어
- 발행일: 2025년 01월 24일
- 챕터: Chapter 6. 학습 관련 기술들
책소개
딥러닝 분야 부동의 베스트셀러! 머리로 이해하고 손으로 익히는 가장 쉬운 딥러닝 입문서 이 책은 딥러닝의 핵심 개념을 ‘밑바닥부터’ 구현해보며 기초를 한 걸음씩 탄탄하게 다질 수 있도록 도와주는 친절한 안내서입니다. 라이브러리나 프레임워크에 의존하지 않고 딥러닝의 기본 개념부터 이미지 인식에 활용되는 합성곱 신경망(CNN)까지 딥러닝의 원리를 체계적으로 설명합니다. 또한 복잡한 개념은 계산 그래프를 활용해 시각적으로 전달하여 누구나 쉽게 이해할 수 있습니다. 이 책은 딥러닝에 첫발을 내딛는 입문자는 물론이고 기초를 다시금 다지고 싶은 개발자와 연구자에게도 훌륭한 길잡이가 되어줄 것입니다.
주요 내용
- 신경망 최적화 기법: SGD를 넘어서다
신경망 학습의 핵심은 손실 함수의 값을 가능한 한 낮추는 매개변수를 찾는 것이다. 이는 매개변수의 최적값을 찾는 최적화(Optimization) 문제로, 신경망에서는 매우 어려운 문제다. 지금까지 사용한 SGD 외에도 더 효율적인 최적화 기법들을 살펴보자.
확률적 경사 하강법(SGD)의 한계
SGD의 기본 원리
지금까지 사용한 확률적 경사 하강법의 수식은 다음과 같다:
\[W \leftarrow W - \eta\frac{\partial L}{\partial W}\]- W: 갱신할 가중치 매개변수
- $\frac{\partial L}{\partial W}$: W에 대한 손실 함수의 기울기
- $\eta$: 학습률 (0.01, 0.001 등)
1
2
3
4
5
6
7
class SGD:
def __init__(self, lr=0.01):
self.lr = lr # 학습률
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
SGD는 기울어진 방향으로 일정 거리만 이동하는 단순한 방법이다.
SGD의 문제점
SGD는 단순하고 구현이 쉽지만, 비등방성 함수에서는 비효율적이다.
.png) $f(x, y) = \frac{1}{20}x^2 + y^2$의 기울기
$f(x, y) = \frac{1}{20}x^2 + y^2$의 기울기
위 함수에서 볼 수 있듯이:
- y축 방향은 가파르지만 x축 방향은 완만하다
- 최솟값은 (0, 0)이지만 대부분의 기울기가 이 지점을 직접 가리키지 않는다
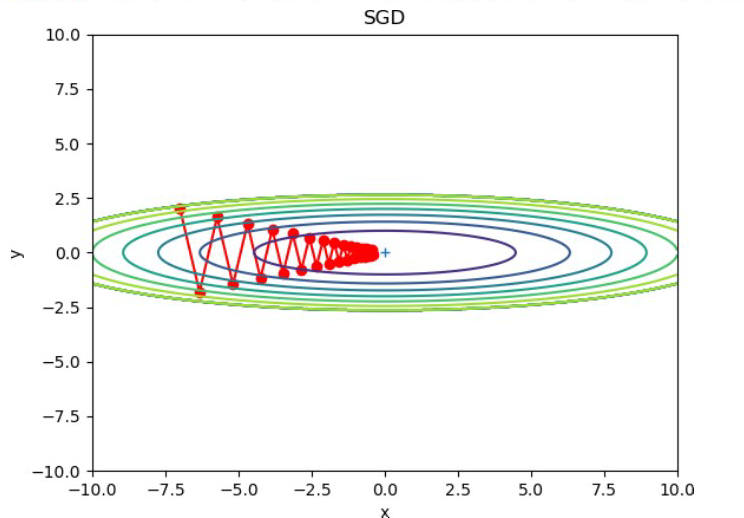 SGD에 의한 최적화 갱신 경로: 최솟값인 (0, 0)까지 지그재그로 이동하니 비효율적이다.
SGD에 의한 최적화 갱신 경로: 최솟값인 (0, 0)까지 지그재그로 이동하니 비효율적이다.
SGD의 한계:
- 비등방성 함수에서 지그재그로 움직여 비효율적
- 방향에 따라 기울기가 다른 함수에서는 탐색 경로가 최적이 아니다
모멘텀(Momentum): 관성을 이용한 최적화
모멘텀의 원리
모멘텀은 물리학의 운동량 개념을 도입한 기법이다.
수식:
\[v \leftarrow \alpha v - \eta\frac{\partial L}{\partial W}\] \[W \leftarrow W + v\]- v: 속도(velocity)
- α: 모멘텀 계수 (보통 0.9)
- 물리학의 관성을 모델링한다
모멘텀의 특징
물리적 의미:
- $\alpha v$ 항: 마찰력 역할 (서서히 감속)
- 기울기 방향으로 힘을 받아 가속
- 이전 이동 방향을 어느 정도 유지
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None # 속도
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
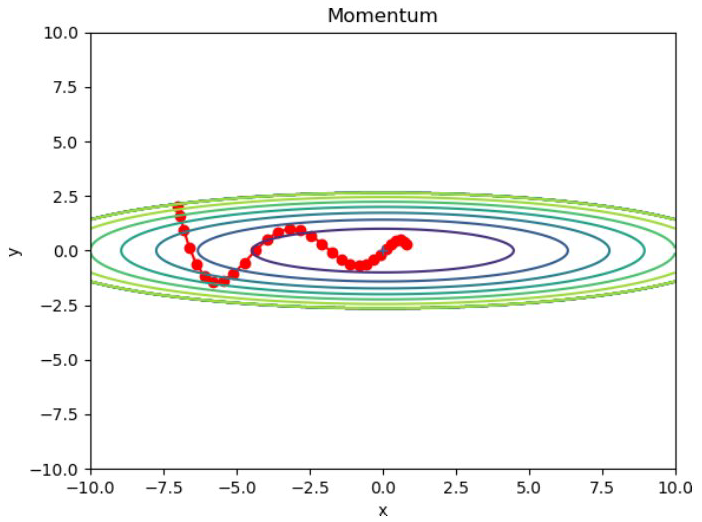 모멘텀에 의한 최적화 갱신 경로
모멘텀에 의한 최적화 갱신 경로
모멘텀의 장점:
- 공이 그릇 바닥을 구르듯 부드러운 움직임
- x축 방향: 일정한 방향으로 지속적 가속
- y축 방향: 상하 진동이 상쇄되어 안정적
- SGD보다 지그재그 움직임이 현저히 감소
AdaGrad: 적응적 학습률 조정
학습률의 중요성과 문제
학습률 설정의 어려움:
- 너무 작으면: 학습 시간이 과도하게 길어짐
- 너무 크면: 발산해서 학습이 실패
AdaGrad의 해결책: 각 매개변수에 맞춤형 학습률을 적용한다.
AdaGrad 수식
\[h \leftarrow h + \frac{\partial L}{\partial W} \odot \frac{\partial L}{\partial W}\] \[W \leftarrow W - \eta\frac{1}{\sqrt{h}}\frac{\partial L}{\partial W}\]- h: 기울기 제곱의 누적합
- $\odot$: 원소별 곱셈
- $\frac{1}{\sqrt{h}}$: 적응적 학습률 조정
핵심 아이디어: 많이 움직인 매개변수는 학습률을 낮추고, 적게 움직인 매개변수는 학습률을 높게 유지한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
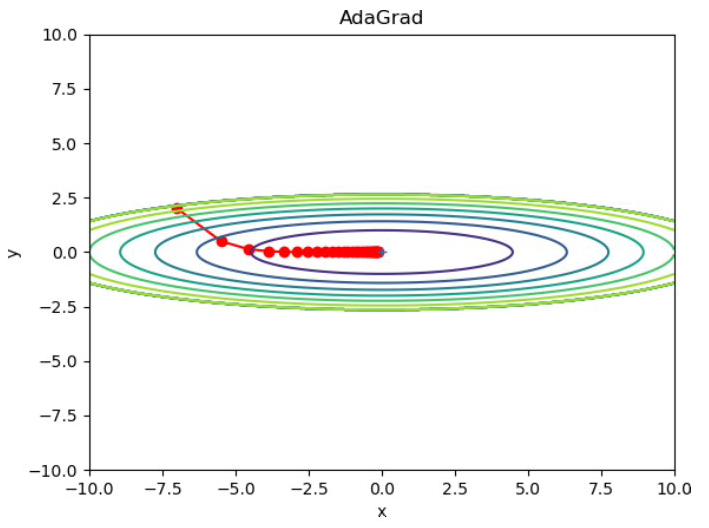 AdaGrad에 의한 최적화 갱신 경로
AdaGrad에 의한 최적화 갱신 경로
AdaGrad의 장점:
- y축 방향의 큰 기울기가 빠르게 감소
- 지그재그 움직임이 크게 줄어듦
- 최솟값을 향해 훨씬 효율적으로 이동
AdaGrad의 한계
문제점: 학습을 진행할수록 갱신 강도가 약해져 무한히 학습하면 갱신이 멈춘다.
해결책: RMSProp - 과거 기울기를 지수이동평균으로 처리하여 먼 과거의 영향을 점진적으로 감소시킨다.
Adam: 모멘텀과 AdaGrad의 융합
Adam의 특징
Adam은 모멘텀과 AdaGrad를 결합한 최신 최적화 기법이다.
주요 특징:
- 모멘텀의 관성 효과
- AdaGrad의 적응적 학습률
- 하이퍼파라미터의 편향 보정
하이퍼파라미터:
- 학습률: 보통 0.001
- β₁: 일차 모멘텀 계수 (0.9)
- β₂: 이차 모멘텀 계수 (0.999)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None # 일차 모멘텀
self.v = None # 이차 모멘텀
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
# 편향 보정된 학습률
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
# 일차 및 이차 모멘텀 업데이트
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
# 매개변수 업데이트
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
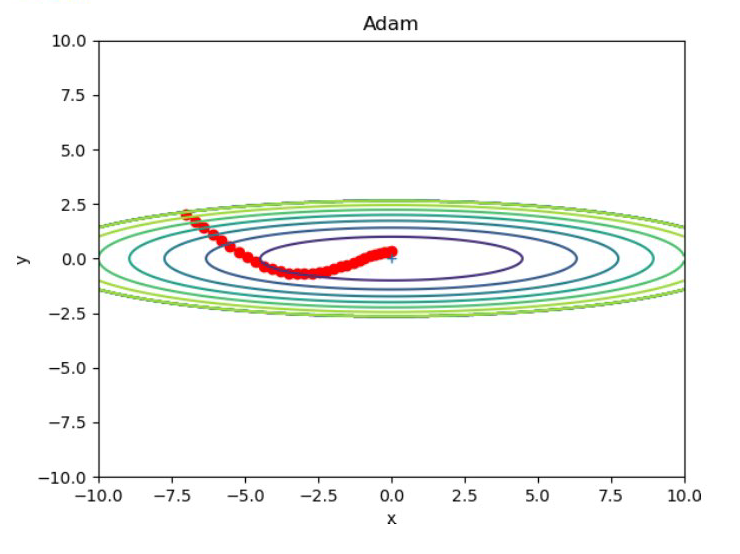 Adam에 의한 최적화 갱신 경로
Adam에 의한 최적화 갱신 경로
Adam의 장점:
- 그릇 바닥을 구르는 듯한 부드러운 움직임
- 모멘텀보다 좌우 흔들림이 적음
- 적응적 학습률 조정의 혜택
- 대부분의 상황에서 안정적인 성능
책에서는 수식 등에 관하여 자세히 다루지 않으며 이해하기 쉽도록 직관적으로 설명한 것이며 자세한 정보는 밑의 코드와 원논문을 참고하는 것이 좋다. Adam 논문
최적화 기법 비교와 선택
MNIST 데이터셋 성능 비교
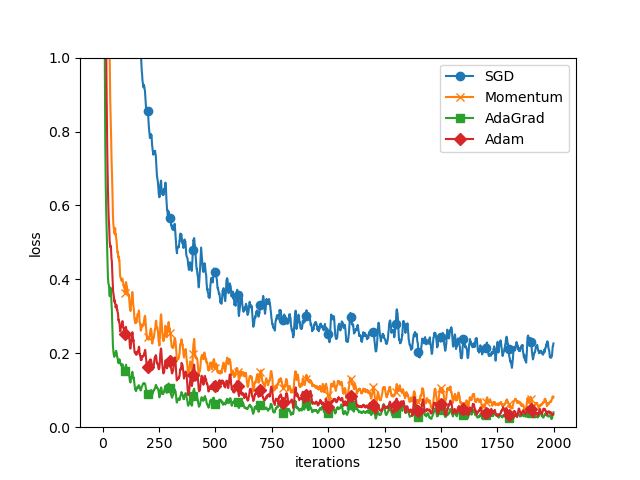 MNIST 데이터셋에 대한 학습 진도 비교
MNIST 데이터셋에 대한 학습 진도 비교
실험 조건:
- 5층 신경망 (각 층 100개 뉴런)
- ReLU 활성화 함수 사용
결과 분석:
- SGD보다 다른 세 기법이 빠르게 학습한다
- 최종 정확도도 더 높게 나타난다
어떤 최적화 기법을 선택할까?
현실적 조언: 모든 문제에서 항상 뛰어난 기법은 없다. 각자의 장단점이 있어 상황에 따라 다르다.
선택 가이드라인:
1. Adam (권장)
- 대부분의 상황에서 안정적
- 하이퍼파라미터 튜닝이 비교적 쉬움
- 빠른 수렴과 좋은 성능
2. SGD + Momentum
- 전통적이고 검증된 방법
- 세밀한 조정이 필요한 경우
- 최종 성능이 중요한 경우
3. AdaGrad
- 희소한 데이터나 특정 문제에 유리
- 학습률 감소가 중요한 경우
실용적 접근:
- Adam으로 시작한다
- 성능이 만족스럽지 않으면 다른 기법들을 시도한다
- 하이퍼파라미터를 조정하며 최적화한다
- 문제의 특성을 고려하여 선택한다
마무리
최적화는 신경망 학습 성능을 좌우하는 핵심 요소다. SGD의 한계를 이해하고 상황에 맞는 최적화 기법을 선택하는 것이 중요하다.
핵심 포인트:
- SGD: 단순하지만 비등방성 함수에서 비효율적
- 모멘텀: 관성을 이용해 지그재그 움직임 감소
- AdaGrad: 적응적 학습률로 매개변수별 최적화
- Adam: 모멘텀과 AdaGrad의 장점을 결합
실무 팁:
- Adam을 기본 선택으로 시작한다
- 여러 기법을 실험하며 최적을 찾는다
- 하이퍼파라미터 튜닝의 중요성을 잊지 않는다
다음 단계에서는 가중치 초기화, 정규화, 배치 정규화 등 학습을 더욱 효과적으로 만드는 기술들을 살펴보겠다.