파이썬과 케라스로 배우는 강화학습 | 강화학습 기초 4
파이썬과 케라스로 배우는 강화학습 Chapter 3 정리
책 정보 📖
- 책 제목: 파이썬과 케라스로 배우는 강화학습
- 글쓴이: 이웅원, 양혁렬, 김건우, 이영무, 이의령
- 출판사: 위키북스
- 발행일: 2020년 04월 07일
- 챕터: Chapter 3. 강화학습 기초 2 : 그리드월드와 다이내믹 프로그래밍
책소개
강화학습의 기초부터 최근 알고리즘까지 친절하게 설명합니다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지기 시작했다. 하지만 처음 강화학습을 공부하는 분들을 위한 쉬운 자료나 강의를 찾아보기 어려웠다. 외국 강의를 통해 어렵게 이론을 공부하더라도 강화학습을 구현하는 데는 또 다른 장벽이 있었다. 이 책은 강화학습을 처음 공부하는 데 어려움을 겪는 독자를 위해 이론부터 코드 구현까지의 가이드를 제시한다.
특히 이번 개정판에서는 텐서플로 버전업에 맞춰서 코드를 업데이트하고 전반적인 이론 및 코드 설명을 개선했다. 그리고 실무에서 많이 활용될 수 있는 연속적 액터-크리틱 알고리즘을 추가했다.
주요 내용
강화학습의 기초 - 다이내믹 프로그래밍, 정책 이터레이션
다이내믹 프로그래밍은 벨만 방정식을 실제로 풀어내는 중요한 방법이다. 이번 포스트에서는 그리드월드 환경을 통해 다이내믹 프로그래밍이 어떻게 작동하는지 알아보고 먼저 정책 이터레이션에 대해 알아본다.
다이내믹 프로그래밍의 이해
다이내믹 프로그래밍의 정의
다이내믹 프로그래밍은 작은 문제가 큰 문제 안에 중첩돼 있는 경우에 작은 문제의 답을 다른 작은 문제에서 이용함으로써 효율적으로 계산하는 방법이다.
강화학습에서는 다음과 같이 적용된다:
- 다이내믹 프로그래밍으로 벨만 기대 방정식을 푸는 것이 정책 이터레이션
- 벨만 최적 방정식을 푸는 것이 가치 이터레이션
순차적 행동 결정 문제 해결 과정
강화학습은 순차적으로 행동을 결정해야 하는 문제를 푸는 방법 중 하나다.
문제 해결 단계
순차적 행동 결정 문제를 풀어나가는 과정은 다음과 같다:
- MDP의 정의: 순차적 행동 문제를 MDP로 전환한다
- 벨만 방정식의 계산: 가치함수를 벨만 방정식으로 반복적으로 계산한다
- 최적 가치함수 + 최적 정책: 최적 가치함수와 최적 정책을 찾는다
벨만 방정식을 푼다는 의미
벨만 방정식을 만족하는 변수의 값을 찾는 것과 같다. 벨만 방정식을 통해 에이전트가 하고 싶은 것은 만족하는 $v_*$를 찾고 싶은 것이다. 이 값을 찾는다면 벨만 방정식을 푼 것이며 에이전트는 최적 가치함수를 알아낸 것이다.
\[v_*(s) = \underset{a}{max}E[R_{t+1} + \gamma v_* (S_{t+1}) | S_t = s, A_t = a]\]다이내믹 프로그래밍의 원리
다이내믹과 프로그래밍의 의미
다이내믹은 동적 메모리의 예시를 통해 이해할 수 있다. 동적 메모리란 메모리가 어느 특정 위치에 어느 크기만큼 정해진 것이 아니라 시간에 따라 변하는 것이다. 따라서 다이내믹이라는 말은 가리키는 대상이 시간에 따라 변한다는 것이다.
프로그래밍이란 말 그대로 계획하는 것으로 여러 프로세스가 다단계로 이뤄지는 것을 말한다.
핵심 아이디어
- 큰 문제 안에 작은 문제들이 중첩된 경우 전체 큰 문제를 작은 문제로 쪼개서 풀겠다는 것이다
- 하나의 프로세스를 대상으로 문제를 푸는 것이 아닌 시간에 따라 다른 프로세스들을 풀어나가기 때문에 다이내믹 프로그래밍이라 부른다
큰 문제를 바로 푸는 것이 아니라 작은 문제들을 풀어나간다. 각각의 작은 문제들이 별개가 아니기 때문에 작은 문제들의 해답을 서로서로 이용할 수 있다. 이 특성을 이용해 계산량을 줄일 수 있다.
반복적 계산 과정
$v_0(s) → v_1(s) → \cdots → v_k(s) → \cdots → v_{\pi}(s)$
- 가치함수를 구하는 과정을 작은 과정으로 쪼개서 반복적으로 계산한다
- 모든 상태에 대해 하며 한 번 계산이 끝나면 모든 상태의 가치함수를 업데이트한다
- 다음 계산은 업데이트된 가치함수를 이용해 다시 똑같은 과정을 반복하는 것이다
- 이전의 정보를 이용해 효율적으로 업데이트할 수 있게 된다
정책 이터레이션은 벨만 기대 방정식을 이용해 순차적인 행동 결정 문제를 풀고, 가치 이터레이션은 벨만 최적 방정식을 이용해 문제를 푼다.
강화학습 알고리즘의 전체 흐름
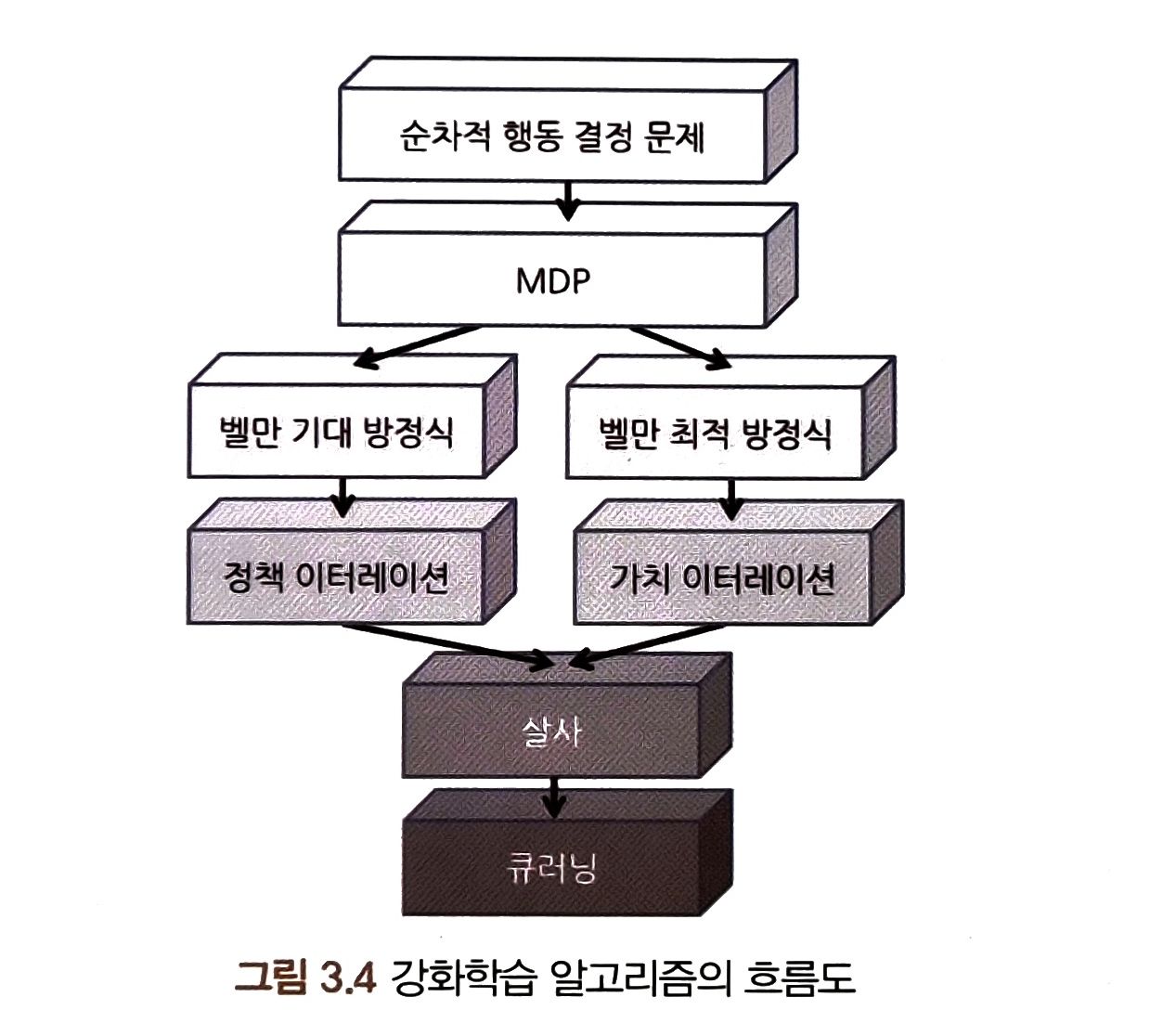 강화학습 알고리즘의 흐름도
강화학습 알고리즘의 흐름도
알고리즘 발전 과정
- MDP로 정의되는 문제에서 목표는 에이전트가 받을 보상의 합을 최대로 하는 것이다
- 가치함수가 에이전트가 받을 보상의 합에 대한 기댓값이기 때문에 가치함수를 통해 이 목표에 얼마나 달성했는지를 판단한다
- 가치함수에 대한 방정식이 벨만 방정식이고 벨만 방정식은 벨만 기대 방정식과 벨만 최적 방정식으로 나뉜다
- 벨만 방정식은 DP로 풀 수 있다
- MDP로 정의되는 문제를 푸는 DP에는 두 가지가 있는데 정책, 가치 이터레이션이다
- 정책, 가치 이터레이션은 후에 살사(SARSA)로 발전한다
- 살사는 오프폴리시(off-policy) 방법으로 변형되어 큐러닝(Q-Learning)으로 이어진다
정책 이터레이션 (Policy Iteration)
정책 이터레이션의 개념
DP의 한 종류로 벨만 기대 방정식을 사용해 MDP로 정의되는 문제를 푼다.
정책을 찾기 위해 무작위로 행동을 정하는 정책과 같이 처음에는 어떤 특정한 정책을 시작으로 계속 발전시켜나가는 방법을 사용한다.
현재의 정책을 평가하고 더 나은 정책으로 발전해야 한다. 정책 이터레이션에서는 평가를 정책 평가, 발전을 정책 발전이라 한다.
어떤 정책이 있을 때 그 정책을 정책 평가 과정을 통해 얼마나 좋은지 평가하고 더 좋은 정책으로 발전시킨다. 발전시킨 정책은 현재의 정책이 되어 위 과정을 반복한다. 이 과정이 무한히 반복되면 정책은 최적 정책으로 수렴한다.
정책 평가 (Policy Evaluation)
정책 평가의 기준
가치함수가 정책이 얼마나 좋은지 판단하는 근거가 된다.
가치함수는 현재의 정책 $\pi$를 따라갔을 때 받을 보상에 대한 기댓값이다. 보상을 어떻게 많이 받을 수 있을지 알아내는 것이 에이전트의 목표이다. 현재 정책에 따라 받을 보상에 대한 정보가 정책의 가치가 되는 것이다.
가치함수 계산
$v_{\pi}(s) = E_{\pi}[R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} \cdots | S_t = s]$
정책에 대한 평가의 기준이 되는 가치함수다. DP에서는 환경에 대한 모든 정보를 알고 문제에 접근하기에 다음 수식을 계산할 수 있다. 하지만 먼 미래를 고려할수록 일어날 수 있는 경우의 수가 기하급수적으로 늘어난다. DP는 이러한 계산량의 문제를 해결한다. 문제를 더 작은 문제로 쪼개고 작은 문제에 저장된 값들을 서로 이용해 계산하기 때문이다.
벨만 기대 방정식을 통한 효율적 계산
$v_{\pi}(s) = E_{\pi}[R_{t+1} + \gamma v_{\pi}(S_{t+1}) | S_t = s]$
벨만 기대 방정식을 통한 효율적인 가치함수의 계산이다. 핵심은 주변 상태의 가치함수와 한 타임스텝의 보상만 고려해 현재 상태의 다음 가치함수를 계산하겠다는 것이다.
한 타임스텝의 보상만 고려하고 주변 상태의 가치함수들을 참 가치함수가 아니다. 따라서 이 값은 실제 값이 아니며 여러 번 반복하여 참 값으로 수렴하게 되는 값이다.
계산 가능한 형태
$v_{\pi}(s) = \sum\limits_{a \in A}\pi(a|s)(r_{(a,s)} + \gamma v_{\pi}(s^{\prime}))$
계산 가능한 합의 형태로 표현한 벨만 기대방정식이다. (상태 변환 확률을 1로 설정했을 경우)
$v_{k+1}(s) = \sum\limits_{a \in A}\pi(a|s)(r_{(a,s)} + \gamma v_{k}(s^{\prime}))$
정책 평가는 $\pi$라는 정책에 대해 반복적으로 수행하는 것이다. 따라서 계산의 단계를 표현할 새로운 변수 k = 1, 2, 3, $\cdots$를 설정한다.
- k번째 가치함수를 통해 k+1번째 가치함수를 계산한다
- k+1번째 가치함수 행렬에서 현재 상태의 가치함수는 다음 상태의 k번째 가치함수를 고려해 계산한다
정책 평가 과정
한 번의 정책 평가 과정은 다음과 같다:
k번째 가치함수 행렬에서 현재 상태 s에서 갈 수 있는 다음상태 $s^\prime$에 저장돼 있는 가치함수 $v_k(s^\prime)$을 불러온다
- $v_k(s^\prime)$에 할인율 $\gamma$를 곱해 그 상태로 가는 행동에 대한 보상 $R_s^a$을 더한다
- $r_{(s, a)} + \gamma v_k(s^\prime)$
- 2번에서 구한 값에 행동을 할 확률, 즉 정책 값을 곱한다
- $\pi(a | s) (r_{(s, a)} + \gamma v_k(s^\prime))$
- 3번을 모든 선택 가능한 행동에 대해 반복하고 그 값들을 더한다
- $\sum\limits_{a \in A} \pi(a | s) (r_{(s, a)} + \gamma v_k(s^\prime))$
4번 과정을 통해 더한 값을 k+1번째 가치함수 행렬의 상태 s자리에 저장한다
- 1~5번 과정을 모든 $s \in S$에 대해 반복한다
위의 과정을 무한히 반복하면 $v_1$로 시작해 참 $v_\pi$가 될 수 있다.
정책 발전 (Policy Improvement)
탐욕 정책 발전
정책 평가를 마쳤다면 정책을 발전시켜야 한다. 발전의 방법에는 정해진 것은 아니며 가장 널리 알려진 탐욕 정책 발전을 소개한다.
정책 평가를 통해 구한 것은 에이전트가 정책을 따랐을 때의 모든 상태에 대한 가치함수다. 이 가치함수를 통해 각 상태에 대해 어떤 행동을 하는 것이 좋은지 알 수 있을까?
큐함수를 사용해 어떤 행동이 좋은지 알 수 있다.
큐함수를 통한 행동 선택
$q_\pi(s, a) = r_{(s,a)} + \gamma v_\pi(s^\prime)$
계산 가능한 형태로 고친 큐함수다. 에이전트는 상태 s에서 선택 가능한 행동의 $q_\pi(s,a)$를 비교하고 그중에서 가장 큰 큐함수를 가지는 행동을 선택하면 된다. 이를 탐욕 정책 발전이라고 한다.
$\pi^\prime (s) = \arg\max_{a \in A} q_\pi(s,a)$
탐욕 정책 발전으로 얻은 새로운 정책이다. argmax는 가장 큰 큐함수를 가지는 행동을 반환하는 함수다. max와는 다르게 행동을 반환한다.
탐욕 정책 발전의 장점
탐욕 정책 발전을 통해 정책을 업데이트하면 이전 가치함수에 비해 업데이트된 정책으로 움직였을 때 받을 가치함수가 무조건 크거나 같다. DP에서 탐욕 정책 발전을 사용하면 단기적으로는 무조건 이익을 본다. 장기적으로는 가장 큰 값의 가치함수를 가지는 최적 정책에 수렴할 수 있다.