파이썬과 케라스로 배우는 강화학습 | 강화학습 기초 5
파이썬과 케라스로 배우는 강화학습 Chapter 3 정리
책 정보 📖
- 책 제목: 파이썬과 케라스로 배우는 강화학습
- 글쓴이: 이웅원, 양혁렬, 김건우, 이영무, 이의령
- 출판사: 위키북스
- 발행일: 2020년 04월 07일
- 챕터: Chapter 3. 강화학습 기초 2 : 그리드월드와 다이내믹 프로그래밍
책소개
강화학습의 기초부터 최근 알고리즘까지 친절하게 설명합니다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지기 시작했다. 하지만 처음 강화학습을 공부하는 분들을 위한 쉬운 자료나 강의를 찾아보기 어려웠다. 외국 강의를 통해 어렵게 이론을 공부하더라도 강화학습을 구현하는 데는 또 다른 장벽이 있었다. 이 책은 강화학습을 처음 공부하는 데 어려움을 겪는 독자를 위해 이론부터 코드 구현까지의 가이드를 제시한다.
특히 이번 개정판에서는 텐서플로 버전업에 맞춰서 코드를 업데이트하고 전반적인 이론 및 코드 설명을 개선했다. 그리고 실무에서 많이 활용될 수 있는 연속적 액터-크리틱 알고리즘을 추가했다.
주요 내용
강화학습의 기초 - 다이내믹 프로그래밍, 정책 이터레이션 예제
이번 포스트에서는 정책 이터레이션을 예제 코드를 살펴본다. 그리드월드 환경에서 동작하는 정책 이터레이션 알고리즘을 단계별로 분석해본다.
코드 구조 개요
정책 이터레이션 구현은 두 개의 주요 파일로 구성된다:
- policy_iteration.py: PolicyIteration 클래스를 포함하며, 클래스에는 정책 이터레이션의 알고리즘 관련 함수와 main 함수가 정의돼 있다
- environment.py: 그리드월드 예제의 화면을 구성하고 상태, 보상 등을 포함한 환경에 대한 정보를 제공하기 위한 함수로 구성돼 있다
다이내믹 프로그래밍의 에이전트는 이론상으로는 최적 정책을 계산하는 것을 스스로 해야 한다. 예제에서는 직접 버튼을 눌러 각 단계를 실행하도록 구성한다.
정책 이터레이션은 정책 평가와 정책 발전으로 이뤄져 있다.
메인 루프
1
2
3
4
5
if __name__ == "__main__":
env = Env()
policy_iteration = PolicyIteration(env)
grid_world = GraphicDisplay(policy_iteration)
grid_world.mainloop()
주요 클래스들
class GraphicDisplay
GUI로 그리드월드 환경을 보여주는 클래스다.
class Env
DP에서 에이전트는 환경의 모든 정보를 알고 있다. 이 정보를 통해 에이전트는 최적 정책을 찾는 계산을 하는 것이다. 계산에 필요한 정보와 함수가 이 클래스로 정의되어 있다.
Env 클래스 상세 분석
주요 멤버 변수
- width, height: 그리드월드 너비와 높이
- possible_actions: 에이전트의 가능한 모든 행동, 예제에서는 좌우상하
주요 메소드
get_all_states
모든 상태 getter로, 에이전트는 이 메소드를 통해 가능한 모든 상태를 알게 된다.
state_after_action
행동 이후의 상태를 반환한다.
1
2
3
4
5
# ACTIONS = [(-1, 0), (1, 0), (0, -1), (0, 1)]
def state_after_action(self, state, action_index):
action = ACTIONS[action_index]
return self.check_boundary([state[0] + action[0], state[1] + action[1]])
# 그리드 영역을 벗어나지 않도록 체크
에이전트가 특정 상태에서 특정 행동을 하면 다음 상태로 가게 되는데, 에이전트가 어떤 다음 상태로 가는지는 환경에 속한 정보이며 다음 메소드로 정의된다.
get_reward
행동 이후의 다음 상태에서 받게 되는 보상을 반환하며, 환경이 주는 보상이다.
1
2
3
def get_reward(self, state, action):
next_state = self.state_after_action(state, action)
return self.reward[next_state[0]][next_state[1]]
PolicyIteration 클래스 상세 분석
주요 멤버 변수
- value_table: 정책 이터레이션은 모든 상태에 대해 가치함수를 계산하기 때문에 2차원 리스트 변수인 멤버 변수를 가진다
- policy_table: 모든 상태에 대해 좌,우,상,하에 해당하는 각 행동의 확률을 담고 있는 리스트로 3차원 리스트다
- discount_factor: 할인율
생성자 (init)
1
2
3
4
5
6
7
8
9
10
11
12
def __init__(self, env):
# 환경에 대한 객체 선언
self.env = env
# 가치함수를 2차원 리스트로 초기화
self.value_table = [[0.0] * env.width for _ in range(env.height)]
# 상 하 좌 우 동일한 확률로 정책 초기화
self.policy_table = [[[0.25, 0.25, 0.25, 0.25]] * env.width
for _ in range(env.height)]
# 마침 상태의 설정
self.policy_table[2][2] = []
# 할인율
self.discount_factor = 0.9
생성자로 env를 통해 환경을 넘겨받는다.
정책 평가 (Policy Evaluation)
policy_evaluation 메소드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 벨만 기대 방정식을 통해 다음 가치함수를 계산하는 정책 평가
def policy_evaluation(self):
# 다음 가치함수 초기화
next_value_table = [[0.00] * self.env.width
for _ in range(self.env.height)]
# 모든 상태에 대해서 벨만 기대방정식을 계산
for state in self.env.get_all_states():
value = 0.0
# 마침 상태의 가치 함수 = 0
if state == [2, 2]:
next_value_table[state[0]][state[1]] = value
continue
# 벨만 기대 방정식
for action in self.env.possible_actions: # 0, 1, 2, 3
next_state = self.env.state_after_action(state, action) # 다음상태(좌표)
reward = self.env.get_reward(state, action) # 행동 이후 받을 보상
next_value = self.get_value(next_state) # 다음 상태의 가치 함수 값
# 수식 3.11 벨만 기대 방정식
value += (self.get_policy(state)[action] *
(reward + self.discount_factor * next_value))
next_value_table[state[0]][state[1]] = value
self.value_table = next_value_table
정책 평가의 핵심
- 모든 상태의 가치함수를 업데이트한다
- 상태 변환 확률은 1이라고 설정
- 수식 3.11: $v_{k+1}(s) = \sum\limits_{a \in A} \pi (a | s) (r_{(s,a)} + \gamma v_k(s^\prime))$
수식의 구성 요소
- get_policy: 각 행동에 대한 확률 값, $\pi(a|s)$
- reward: 다음 상태로 갔을 때 받을 보상, $r_{(s, a)}$
- discount_factor * next_value: 다음 상태의 가치함수의 할인한 값, $\gamma v_k(s^\prime)$
정책이 각 행동에 대한 확률을 나타내기 때문에 모든 행동에 대해 value를 계산하고 더하면 기댓값을 계산한 것이 된다.
정책 발전 (Policy Improvement)
policy_improvement 메소드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 현재 가치 함수에 대해서 탐욕 정책 발전
def policy_improvement(self):
next_policy = self.policy_table
for state in self.env.get_all_states():
if state == [2, 2]:
continue
value_list = []
# 반환할 정책 초기화
result = [0.0, 0.0, 0.0, 0.0]
# 모든 행동에 대해서 [보상 + (할인율 * 다음 상태 가치함수)] 계산
for index, action in enumerate(self.env.possible_actions):
next_state = self.env.state_after_action(state, action)
reward = self.env.get_reward(state, action)
next_value = self.get_value(next_state)
value = reward + self.discount_factor * next_value
value_list.append(value)
# 받을 보상이 최대인 행동들에 대해 탐욕 정책 발전
max_idx_list = np.argwhere(value_list == np.amax(value_list))
max_idx_list = max_idx_list.flatten().tolist()
prob = 1 / len(max_idx_list) # 가장 좋은 행동들의 확률을 동일하게
for idx in max_idx_list:
result[idx] = prob
next_policy[state[0]][state[1]] = result
self.policy_table = next_policy
정책 발전의 핵심
- 에이전트는 새로운 가치함수를 통해 정책을 업데이트한다
- 탐욕 정책 발전을 사용하여 정책을 업데이트한다
- 현재 상태에서 가장 좋은 행동이 여러 개일 경우를 고려해 가장 좋은 행동들을 동일한 확률로 선택하는 정책으로 업데이트한다
핵심 계산
- value: $r_{(s,a)} + \gamma v_k(s^\prime)$
- max 함수를 통해 가장 큰 값을 찾아내고 argwhere를 통해 모든 인덱스를 반환한다
기타 주요 메소드
get_action 메소드
1
2
3
4
5
# 특정 상태에서 정책에 따라 무작위로 행동을 반환
def get_action(self, state):
policy = self.get_policy(state)
policy = np.array(policy)
return np.random.choice(4, 1, p=policy)[0]
에이전트가 현재 정책에 따라서 움직이기 위한 메소드다.
- np.random.choice(4, 1, p=policy)[0]: 첫 번째 인자는 행동의 개수, 두 번째 인자는 몇 개의 행동을 샘플링할지, 각 행동을 얼마의 확률에 기반해서 샘플링할지를 정한다
get_policy와 get_value
- get_policy: 해당 상태에 대한 정책을 반환
- get_value: 해당 상태에 해당하는 가치함수를 반환
정책 이터레이션 실행 결과
첫 실행 화면
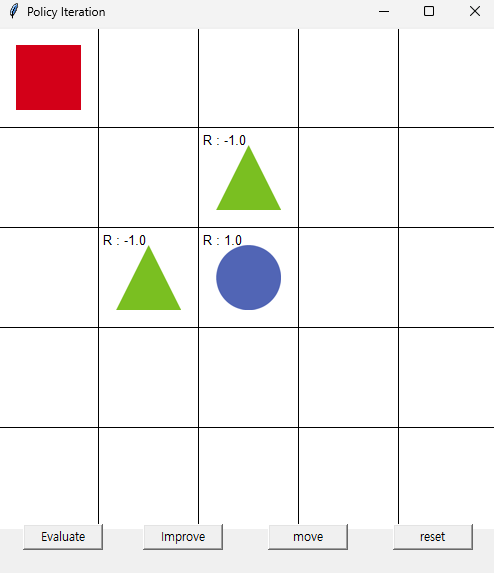 첫 실행 화면
첫 실행 화면
3번의 Evaluate와 Improve 수행 후
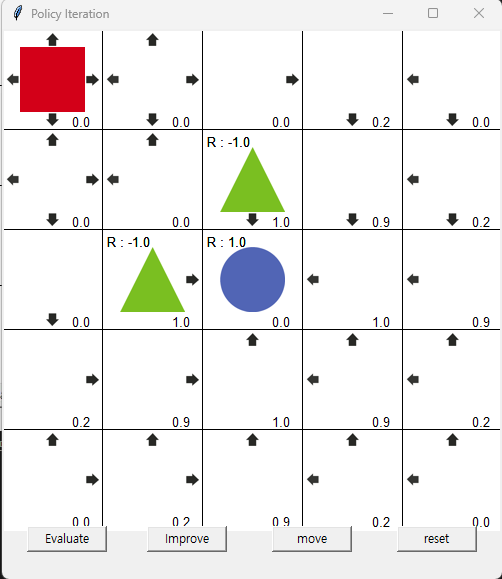 3번의 Evaluate와 Improve를 수행한 화면
3번의 Evaluate와 Improve를 수행한 화면
최적 정책 도출
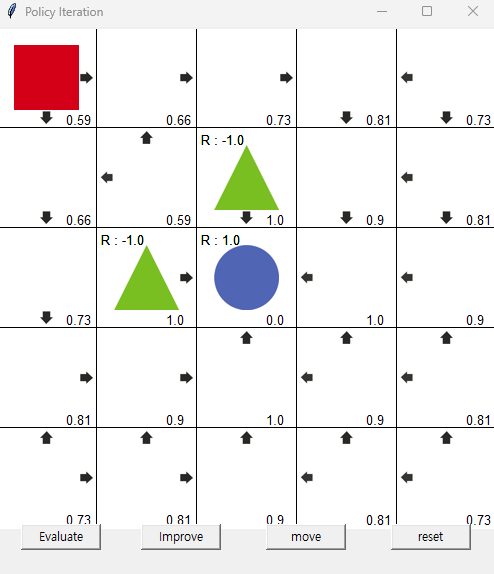 정책 이터레이션의 최적 정책
정책 이터레이션의 최적 정책
정책 이터레이션의 특징
정책 이터레이션에서 정책 평가는 여러 번에 걸쳐서 해야 현재 정책에 대한 정확한 가치함수를 얻을 수 있다. 하지만 목적이 최적 정책을 찾는 것이라면 극단적으로는 평가 한 번에 발전 한 번씩 해도 최적 정책에 수렴한다.
최적 정책은 탐욕 정책인 경우가 많지만 그리드월드에서는 항상 최적 정책이 탐욕 정책이 아닐 수도 있다는 것을 알 수 있다.