파이썬과 케라스로 배우는 강화학습 | 강화학습 기초 7
파이썬과 케라스로 배우는 강화학습 Chapter 4 정리
책 정보 📖
- 책 제목: 파이썬과 케라스로 배우는 강화학습
- 글쓴이: 이웅원, 양혁렬, 김건우, 이영무, 이의령
- 출판사: 위키북스
- 발행일: 2020년 04월 07일
- 챕터: Chapter 4. 강화학습 기초 3: 그리드월드와 큐러닝
책소개
강화학습의 기초부터 최근 알고리즘까지 친절하게 설명합니다! ‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지기 시작했다. 하지만 처음 강화학습을 공부하는 분들을 위한 쉬운 자료나 강의를 찾아보기 어려웠다. 외국 강의를 통해 어렵게 이론을 공부하더라도 강화학습을 구현하는 데는 또 다른 장벽이 있었다. 이 책은 강화학습을 처음 공부하는 데 어려움을 겪는 독자를 위해 이론부터 코드 구현까지의 가이드를 제시한다.
특히 이번 개정판에서는 텐서플로 버전업에 맞춰서 코드를 업데이트하고 전반적인 이론 및 코드 설명을 개선했다. 그리고 실무에서 많이 활용될 수 있는 연속적 액터-크리틱 알고리즘을 추가했다.
주요 내용
- 강화학습의 기초 - 몬테카를로 예측
강화학습과 다이내믹 프로그래밍의 가장 큰 차이점은 강화학습이 환경의 모델을 몰라도 환경과의 상호작용을 통해 최적 정책을 학습한다는 것이다. 이번 포스트에서는 강화학습의 핵심 개념인 몬테카를로 예측에 대해 알아보자.
강화학습의 구조: 예측과 제어
강화학습에서 에이전트는 환경과의 상호작용을 통해 주어진 정책에 대한 가치함수를 학습할 수 있는데, 이를 예측이라 한다. 또한 가치함수를 토대로 정책을 끊임없이 발전시켜 나가서 최적 정책을 학습하려는 것이 제어다.
강화학습의 주요 방법들
- 예측: 몬테카를로 예측, 시간차 예측
- 제어: 시간차 제어인 살사(SARSA), 오프폴리시 제어인 큐러닝(Q-Learning)
사람의 학습 방법과 강화학습
다이내믹 프로그래밍의 한계
다이내믹 프로그래밍의 상태 수가 증가할수록, 차원이 증가할수록 계산복잡도가 기하급수적으로 증가하는 이유는 무엇일까?
→ 환경에 대한 정확한 지식을 가지고 모든 상태에 대해 동시에 계산을 진행하기 때문이다. 환경의 모든 상태에 대해 가능한 모든 상황을 고려해서 계산하는 것이다.
강화학습은 환경의 모델 없이 환경이라는 시스템의 입력과 출력 사이의 관계를 학습한다. 입력은 에이전트의 상태와 행동이고 출력은 보상이다.
강화학습의 학습 과정
강화학습은 다음과 같은 과정을 반복한다:
- 일단 해보고
- 자신을 평가하며
- 평가한 대로 자신을 업데이트하며
- 이 과정을 반복한다
계산을 통해서 가치함수를 알아내는 것이 아니라 에이전트가 겪은 경험으로부터 가치함수를 업데이트하는 것이다.
강화학습의 예측과 제어
다이내믹 프로그래밍을 적용할 수 있는 문제는 많지 않다. 사람은 어떤 것을 판단할 때 항상 정확한 정보를 근거로 판단하지 않는다. 다이내믹 프로그래밍보다 정확하지는 않지만 적당한 추론을 통해 학습하는 것이 실제 세상에서는 더 효율적이다.
강화학습에서는 적당한 추론을 통해 원래 참 가치함수의 값을 예측하는 것이다. 정책 이터레이션에서 정책 평가는 현재 정책을 따랐을 때 참 가치함수를 구하는 과정이다. 이 과정을 강화학습에서는 예측이라고 한다. 또한 예측과 함께 정책을 발전시키는 것을 제어라고 부른다.
몬테카를로 근사의 이해
몬테카를로 근사란?
원의 넓이는 보통 원의 넓이 방정식을 통해 구한다. 하지만 원의 넓이 방정식을 모른다면 어떻게 구할까?
→ 몬테카를로 근사라는 방법을 사용한다.
몬테카를로라는 말은 ‘무작위로 무엇인가를 해본다’이고 근사라는 것은 원래의 값은 모르지만 ‘샘플’을 통해 ‘원래의 값에 대해 이럴 것이다’라고 추정하는 것이다.
추정한 값은 원래의 값과 정확히 같지는 않지만 무작위로 많이 하면 점점 원래의 값과 비슷해진다.
몬테카를로 근사 예시
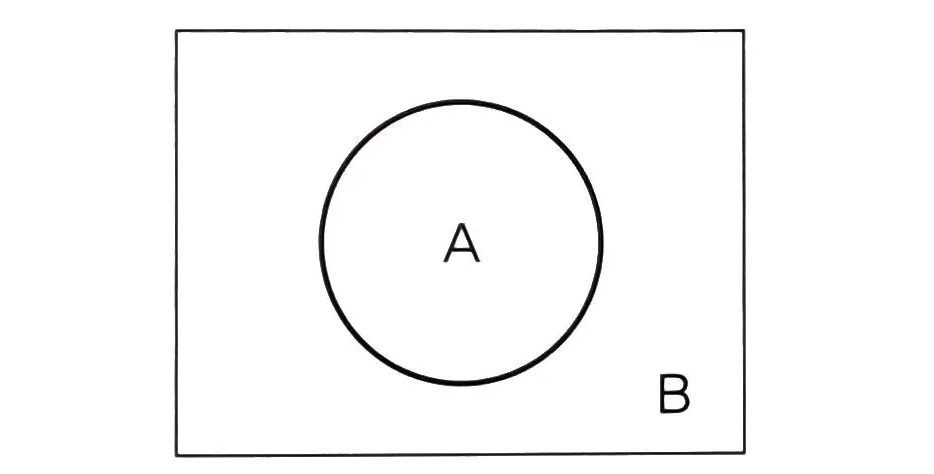 종이 위에 그려진 원의 넓이를 구하려면 어떻게 해야 할까?
종이 위에 그려진 원의 넓이를 구하려면 어떻게 해야 할까?
종이 위에 그려진 원의 넓이를 구하는 방법:
- 원의 넓이 S(A)를 구하는 것이 목표이며 종이의 넓이 S(B)는 안다고 가정한다
- S(A)를 몬테카를로 근사로 계산하는 방법은 간단하다:
- 원이 그려진 종이 위에 점을 무작위로 계속 뿌린다
- 뿌린 전체 점들 중에서 A에 들어가 있는 점의 비율을 구하면 S(B)를 통해 S(A)를 추정할 수 있다
- 뿌린 점의 비율로 S(A)/S(B)를 근사하는 것이다
점 n개를 뿌렸을 때 k개가 원안에 있을 때 몬테카를로 근사를 통해 다음과 같이 된다.
몬테카를로 근사의 특징
- 평균을 취함으로써 근사하는 것이다
- 몬테카를로 근사의 특성 중 하나는 무한히 반복하면 원래의 값과 동일해진다는 것이다
- 샘플링 숫자 n이 무한대로 가면 샘플링한 값의 평균이 원래의 값과 동일해진다
- 더 많은 샘플을 사용할수록 오차는 적어진다
- 방정식을 몰라도 원래 값을 추정할 수 있다는 장점이 있다
- 방정식을 몰라도 반복하기만 하면 답을 구할 수 있다는 장점은 강화학습에 그대로 이용된다
몬테카를로 예측
샘플링과 몬테카를로 예측
몬테카를로 근사를 사용해 가치함수를 추정해보자.
- 가치함수를 추정할 때는 에이전트가 한 번 환경에서 에피소드를 진행하는 것이 샘플링이다
- 샘플링을 통해 얻은 샘플의 평균으로 참 가치함수의 값을 추정한다
- 이때 몬테카를로 근사를 사용하는 것을 몬테카를로 예측이라고 한다
- 샘플링 + 평균 → 가치함수 추정
가치함수의 정의 vs 몬테카를로 예측
$v_\pi(s) = E_\pi [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} \cdots | S_t = s]$
가치함수의 정의는 현재 상태로부터 받을 보상을 시간별로 할인해서 더한 다음 그것의 기댓값을 계산한 것이다. 정책 이터레이션의 정책 평가에서는 이 가치함수를 구하기 위해 벨만 기대 방정식을 이용했다. 아무리 효율적이라도 정책 이터레이션은 기댓값을 ‘계산’한 것이다.
샘플링을 통한 예측
샘플링을 통해 기댓값을 계산하지 않고 샘플들의 평균으로 가치함수를 ‘예측’하려면 어떻게 해야 할까?
→ 현재 정책에 따라서 계속 행동해보면 된다. 현재 정책에 따라 행동하면 그에 따라서 보상을 받는다.
반환값과 몬테카를로 예측
$G_t = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{T-t+1} R_T$
끝이 있는 에피소드에서 반환값의 정의다. 받은 보상들을 할인해서 더한 값이 MDP에서 설명한 반환값이다.
- 에피소드는 끝이 있다고 가정한다
- 에이전트가 현재 정책을 토대로 한 에피소드를 진행하면 반환값은 에피소드 동안 지나쳐 왔던 각 상태마다 존재한다
- 한 번의 에피소드를 진행해보는 것은 원의 넓이를 구할 때 점 한 번을 뿌리는 것과 동일하다
- 한 번의 에피소드를 통해 반환값을 얻어도 한 번의 에피소드로는 추정이 불가능하다
- 몬테카를로 예측을 위해서는 각 상태에 대한 반환값들이 많이 모여야 한다
- 반환값들의 평균을 통해 참 가치함수의 값을 추정해야 하기 때문이다
환경 모델 vs 몬테카를로 예측
벨만 기대 방정식을 계산하려면 조건이 필요하다. 바로 환경의 모델인 상태 변환 확률과 보상 함수를 알아야 한다는 것이다. 이것은 원의 넓이 방정식을 알아야 하는 것과 마찬가지다. 문제는 원의 방정식보다 환경의 모델이 훨씬 복잡해질 것이라는 것이다.
\[v_\pi(s) \sim \frac{1}{N(s)} \sum_{i = 1}^{N(s)}G_i(s)\]몬테카를로 예측에서는 환경의 모델을 알아야 하는 $E_\pi$를 계산하지 않는다. 환경의 모델을 몰라도 여러 에피소드를 통해 구한 반환값의 평균을 통해 $v_\pi(s)$를 추정한다.
- 여러 번의 에피소드에서 s라는 상태를 방문해 얻은 반환값들의 평균을 통해 참 가치함수를 추정하는 식이다
- N(s)는 상태 s를 여러 번의 에피소드 동안 방문한 횟수다
- $G_i(s)$는 그 상태를 방문한 i번째 에피소드에서 s의 반환값이다
- 현재 정책에 따라 무수히 많은 에피소드를 진행하면 현재 정책을 따랐을 때 지날 수 있는 모든 상태에 대해 충분한 반환값들을 모을 수 있다
- 각 상태에 모인 반환값들의 평균을 내면 상당히 정확한 가치함수의 값을 얻을 수 있다
몬테카를로 예측의 업데이트 방식
이동평균을 통한 업데이트
\[V_{n+1} = \frac{1}{n}\sum_{i=1}^{n} G_i = \frac{1}{n}(G_n + \sum_{i=1}^{n-1}G_i)\]편의상 상태에 대한 표현은 생략한다. n개의 반환값을 통해 평균을 취한 가치함수를 $V_{n+1}$이라고 한다. 가치함수를 대문자로 표현한 것은 참 가치함수가 아닌 측정한 오차가 내포된 가치함수라는 의미다.
수식 전개
\[= \frac{1}{n}(G_n + (n-1)\frac{1}{n-1}\sum_{i=1}^{n-1}G_i)\]식을 전개하면 다음과 같게 만들 수 있다. $\frac{1}{n-1}\sum_{i=1}^{n-1}G_i$은 이전의 가치함수 $V_{n}$이다.
\[= \frac{1}{n}(G_n + (n-1)V_n) = V_n + \frac{1}{n}(G_n - V_n)\]몬테카를로 예측의 업데이트 특징
- 몬테카를로 예측 동안에 계속 새로운 반환값이 들어와 평균을 취할 때 어떤 식으로 평균을 취하는지를 보여준다
- 어떤 상태의 가치함수는 샘플링을 통해 에이전트가 그 상태를 방문할 때마다 업데이트하게 된다
- 원래 가지고 있던 가치함수 $V(s)$ 값에 $\frac{1}{n}(G(s) - V(s))$ 값을 더함으로써 업데이트하는 것이다
- 이렇게 시간에 따라 평균을 업데이트해나가는 것을 이동평균이라고 한다
기본 업데이트 식
\[V(s) \leftarrow V(s) + \frac{1}{n}(G(s) - V(s))\]몬테카를로 예측에서 가치함수의 업데이트 식이다:
- G(s) - V(s): 오차
- 1/n: 스텝사이즈로서 업데이트할 때 오차의 얼마를 가지고 업데이트하는지를 정하는 것
- n = 1이면 대체의 개념이 된다
- 업데이트의 목표가 되는 G(s)가 시간에 따라 많이 변화할지라도 1/n이라는 스텝사이즈를 곱하면서 더하기 때문에 결국 반환값의 평균으로 수렴한다
일반화된 업데이트 식
\[V(s) \leftarrow V(s) + \alpha(G(s) - V(s))\]몬테카를로 예측에서 가치함수 업데이트의 일반식이다. 일반적으로 스텝사이즈는 $\alpha$로 표현한다.
- 스텝사이즈는 일정한 상수일 수 있으며 일정한 숫자로 고정한다는 것은 과거의 반환값보다 현재 에피소드로부터 얻은 반환값을 더 중요하게 보고 업데이트한다는 것이다
- 스텝사이즈가 클수록 과거에 얻은 반환값을 지수적으로 감소시킨다
- 몬테카를로 예측 이후의 모든 강화학습 방법에서 가치함수를 업데이트하는 것은 다음 수식의 변형일 뿐이다
스텝사이즈를 고정하는 경우
스텝사이즈를 고정하는 것이 좋은 경우:
- 환경이 지속적으로 변화하는 경우
- 몬테카를로 예측을 통해 참 가치함수를 구하는 과정에 정책을 변화시켜 그에 따라 에이전트가 얻는 보상이 달라지는 경우
업데이트 구성 요소
- G(s) = 업데이트 목표
- α(G(s) - V(s)) = 업데이트 크기
- 가치함수 입장에서 업데이트를 통해 도달하려는 목표는 반환값이다
- 한 번에 목표점으로 가는 것이 아닌 스텝사이즈를 곱한 만큼만 가는 것이다
몬테카를로 예측의 수렴성
몬테카를로 예측에서 이 업데이트식을 통해 에피소드 동안 경험했던 모든 상태에 대해 가치함수를 업데이트한다. 어떤 상태의 가치함수가 업데이트될수록 가치함수는 현재 정책에 대한 참 가치함수에 수렴해간다.
후의 시간차 예측 방법에서는 1번 업데이트의 목표가 변하고 나머지는 동일하다.